在我的另一篇文章中,我介绍了使用label+taint+daemonset方式来部署高可用的ingress controller,利用的就是daemonset会在不同节点部署一个pod的特性来实现在指定的两台用于七层反向代理的ingress controller的部署。那么使用Deployment能不能实现相同的功能呢?答案也是可以的,就是利用比nodeSelector更加强大的nodeAffinity以及podAntiAffinity,如果光使用nodeAffinity,这种情况下pod是调度到我们指定的节点了,但是有可能会调度到同一台机器上,例如有两个机器用于部署ingress controller,我们在deployment中设置replicas=2,那么在apply之后,就有可能这两个pod跑到同一个node上。一旦这个机器异常宕机,即便是k8s会调度这个pod到另外一台机器上,但是可能会造成瞬时不可用的情况。另一个机器也处于闲置状态。所以进一步的使用pod间的反亲和性podAntiAffinity来使得这两个pod部署到不同的节点。pod的亲和性podAffinity在官方文档中举的例子就是后端代码和redis要部署在同一台机器上。反亲和性在官方文档中举的例子是同一套后端代码不要调度到同一个node上。
这个时候我们思路就展开了,可以结合nodeAffinity与podAntiAffinity实现daemonset的效果,下面看一下配置文件:
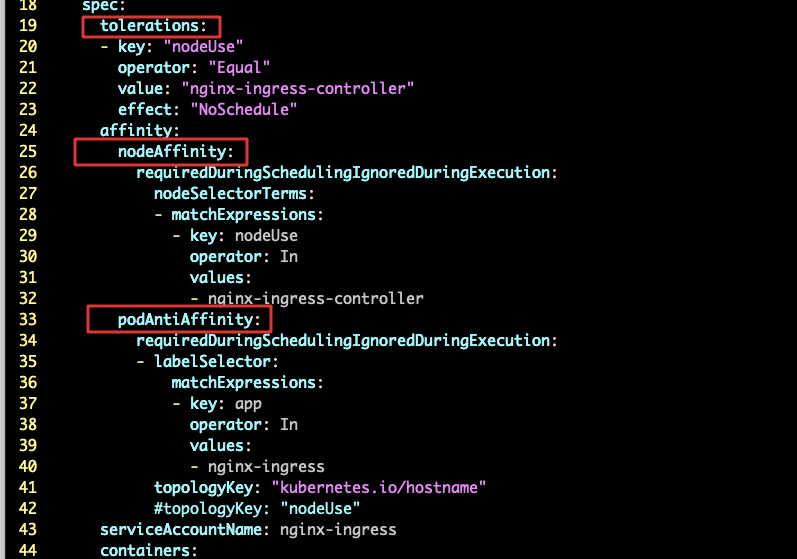
与另一篇文章中的环境一致,一共有两台ECS用于部署nginx ingress controller,为了不使其他工作pod调度到这两个机器上,分别给这两台机器加上了一个taint nodeUse=nginx-ingress-controller:NoSchedule,所以第一步,先加上对这个taint的toleration,第二步,就是nodeAffinity,下面的意思就是选择打了标签key为nodeUse value为nginx-ingress-controller的node。第三步,加上podAntiAffinity,下面的意思就是如果pod打了key为app,value为nginx-ingress的label,那么就不要将pod调度到这个节点上。其中topologyKey为必须字段,这个字段的意思就是需要指定一个label,这个label在将要调度节点的集合中都存在,这里就指定一个无关痛痒的kubernetes.io/hostname,这个label也是默认加上去的,节点上都有。
通过以上三个属性的指定,就选择到了一个打了nodeUse=nginx-ingress-controller:NoSchedule 的taint的节点,同时这个节点还需要有一个key为nodeUse value为nginx-ingress-controller的标签。最后如果这个节点上已经运行了一个打了key为app,value为nginx-ingress的pod,那么其他的副本pod将不会调度到这个节点上。这样就实现了我们的目的。
最后运行一下看看:

可以看到,pod被调度到了不同的节点。因为这里准备了两个节点,那么就将replicas设置为2,如果设置为大于2,那么可以想到,其他的pod将不能调度成功,如果将replicas设置为4,可以看到有两个pod处于pending状态:

describe一下看看:

可以看到,events中说两个节点不满足pod affinity/anti-affinity,也就是已经调度了的pod的节点,不能再调度pod到上面了,3个节点不满足node selector,因为一共5个节点,其他三个没有打nodeUse=nginx-ingress-controller的label,所以这两个pod将一直无法进行调度。
最后,亲和性选择只会在调度的时候生效,如果在调度之后删除了节点上的label,那么已经在这个节点上的pod不会被删除
问题:
可以很容易的感受到,pod间的亲和性与反亲和性相比于节点的亲和性和反亲和性需要进行大量的比对,在大规模集群中的调度性能会成问题,所以官方也是建议在大规模的集群中最好不要使用,否则调度起来很慢。而且要进行pod间的亲和性和反亲和性的比对,pod就有状态了,所以最好使用statefulset进行部署