在前面的文章中,我介绍了安装ingress controller的几种方法,最常见的就是使用DaemonSet+label+taint的方式来部署高可用的ingress,部署完ingress controller的pod之后,我们需要创建一个service暴露端口出来,例如service使用nodePort方式暴露23456,对应ingress controller的80端口,使用nodePort方式暴露34567,对应ingress controller的443端口,然后slb监听80,转发到ingress node的23456端口,slb监听443,转发到ingress node的34567端口。这本身并没有什么可说的,但是这里注意一个点,就是service的service.spec.externalTrafficPolicy特性默认值为Cluster,这就使得网络包到达任意一个节点的时候,lvs将会把网络包负载均衡到任意一个后端ingress controller pod中。
例如kube-proxy 使用的是ipvs模式的话,那么创建完ingress的service之后,使用ipvsadm查看
(这里我使用daemonset方式部署了3个ingress controller的pod):
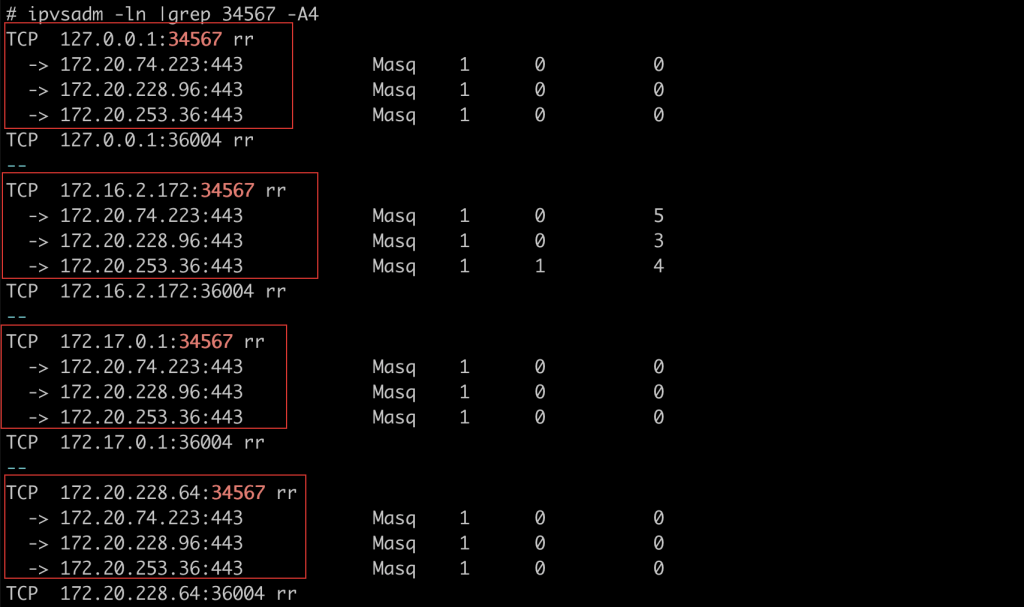
可以看到,如果一个请求到达node01,那么就有可能这个请求又会被转发到node02或者node03上的pod,这么看来就有个性能消耗问题,因为到达node01的请求就由node01上的pod来处理就好了,而现在可能又被转发到别的节点。
还有一个更严重的问题就是externalTrafficPolicy如果为Cluster的话,请求的源IP将会被SNAT,这样到达ingress controller的pod之后,ingress的pod看到的源ip是节点的ip而不是真正的clientIP,这样对于我们通过请求源ip来做一些统计分析,或者后端服务通过x-forwarded-for头部取出源ip来做业务判断都会出问题。都是不对的。
这个时候,我们在创建service的时候,指定externalTrafficPolicy为Local,这样请求过来的时候,只会转发到当前节点的pod上,这样避免了转发性能消耗,另一个是不会将源IP SNAT,这样ingress pod拿到的clientIP就是真正的客户端IP(阿里云四层监听是将源IP透传过来的。)
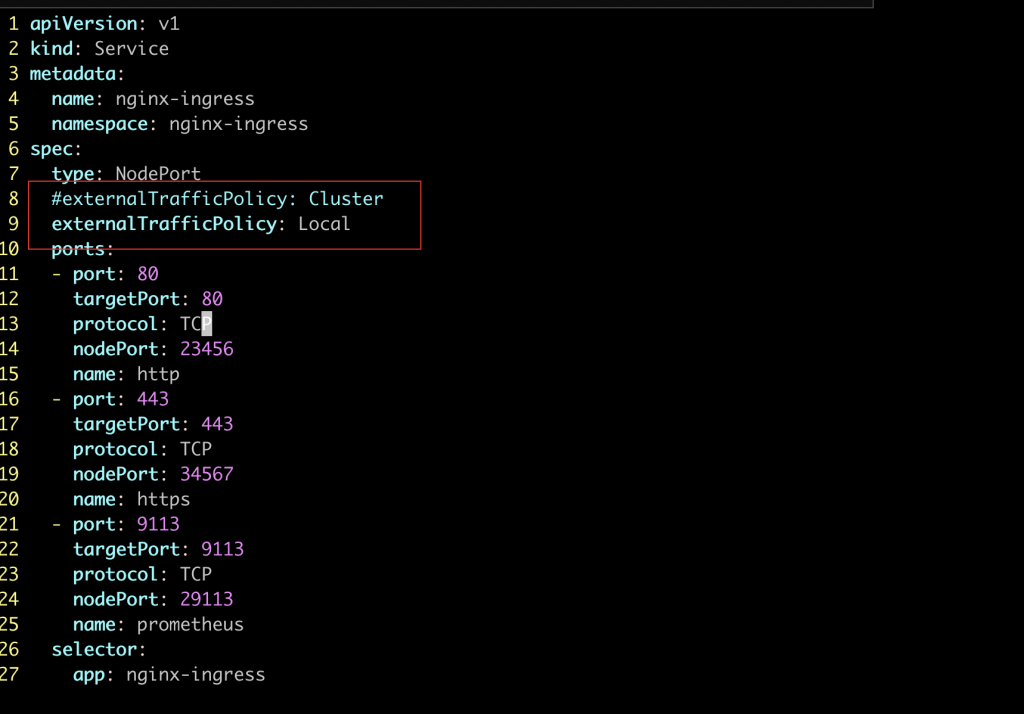
apply之后,我们再使用ipvsadm看下转发规则:
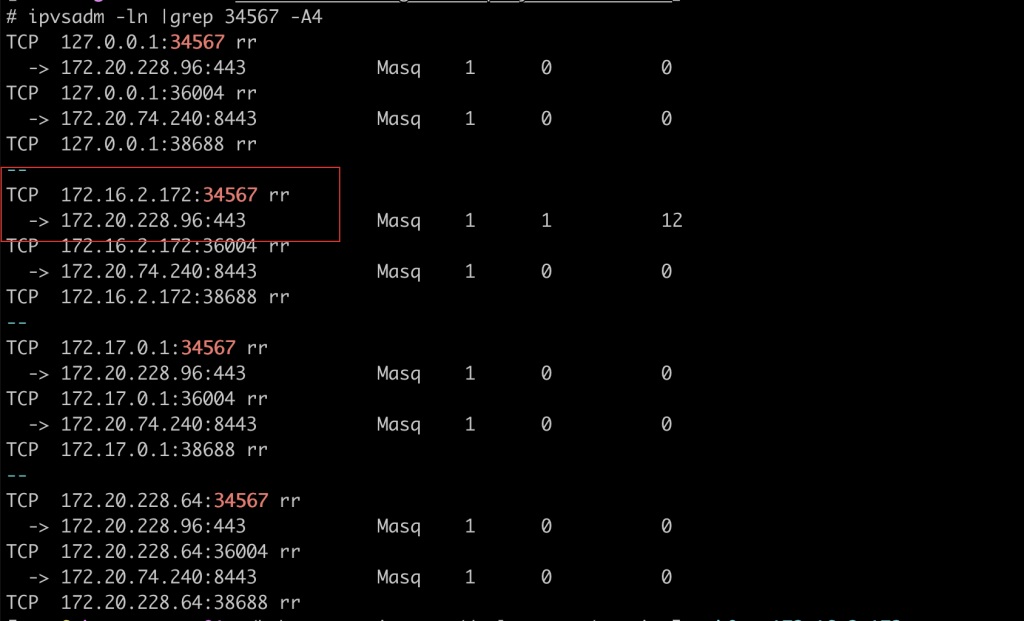
可以看到,lvs转发到后端的pod只剩一个了,而这个IP地址就是当前节点的pod的ip地址,而在其他节点上使用ipvsadm查看也是同样的规则,就是只会转发到当前节点上的pod中。

在nginx ingress pod中记录访问日志,进行查看,可以看到clientip就是真正的公网IP,而不是内网ip,这样我们传递给后端服务的pod的x-forwarded-for头部才是真正的客户端地址。而不是nginx ingress controller的集群内部地址了。
